






















Create a collaborative filtering system
| Time: 45 min | Level: Intermediate |
|---|
Every time Spotify recommends the next song from a band you’ve never heard of, it uses a recommendation algorithm based on other users’ interactions with that song. This type of algorithm is known as collaborative filtering.
Unlike content-based recommendations, collaborative filtering excels when the objects’ semantics are loosely or unrelated to users’ preferences. This adaptability is what makes it so fascinating. Movie, music, or book recommendations are good examples of such use cases. After all, we rarely choose which book to read purely based on the plot twists.
The traditional way to build a collaborative filtering engine involves training a model that converts the sparse matrix of user-to-item relations into a compressed, dense representation of user and item vectors. Some of the most commonly referenced algorithms for this purpose include SVD (Singular Value Decomposition) and Factorization Machines. However, the model training approach requires significant resource investments. Model training necessitates data, regular re-training, and a mature infrastructure.
Methodology
Fortunately, there is a way to build collaborative filtering systems without any model training. You can obtain interpretable recommendations and have a scalable system using a technique based on similarity search. Let’s explore how this works with an example of building a movie recommendation system.
Implementation
To implement this, you will use a simple yet powerful resource: Qdrant with Sparse Vectors.
Notebook: You can try this code here
Setup
You have to first import the necessary libraries and define the environment.
import os
import pandas as pd
import requests
from IPython.display import display, HTML
from qdrant_client import models,QdrantClient
from qdrant_client.http.models import PointStruct, SparseVector, NamedSparseVector
from collections import defaultdict
from dotenv import load_dotenv
load_dotenv()
# OMDB API Key
omdb_api_key = os.getenv("OMDB_API_KEY")
# Collection name
collection_name = "movies"
# Set Qdrant Client
qdrant_client = QdrantClient(
os.getenv("QDRANT_HOST"),
api_key=os.getenv("QDRANT_API_KEY")
)
Define output
Here, you will configure the recommendation engine to retrieve movie posters as output.
# Function to get movie poster using OMDB API
def get_movie_poster(imdb_id, api_key):
url = f"https://www.omdbapi.com/?i={imdb_id}&apikey={api_key}"
response = requests.get(url)
if response.status_code == 200:
data = response.json()
return data.get('Poster', 'No Poster Found'), data
return 'No Poster Found'
Prepare the data
Load the movie datasets. These include three main CSV files: user ratings, movie titles, and OMDB IDs.
# Load CSV files
ratings_df = pd.read_csv('data/ratings.csv', low_memory=False)
movies_df = pd.read_csv('data/movies.csv', low_memory=False)
links = pd.read_csv('data/links.csv')
# Convert movieId in ratings_df and movies_df to string
ratings_df['movieId'] = ratings_df['movieId'].astype(str)
movies_df['movieId'] = movies_df['movieId'].astype(str)
# Add step to convert imdbId to tt format with leading zeros
links['imdbId'] = 'tt' + links['imdbId'].astype(str).str.zfill(7)
# Normalize ratings
ratings_df['rating'] = (ratings_df['rating'] - ratings_df['rating'].mean()) / ratings_df['rating'].std()
# Merge ratings with movie metadata to get movie titles
merged_df = ratings_df.merge(movies_df[['movieId', 'title']], left_on='movieId', right_on='movieId', how='inner')
# Aggregate ratings to handle duplicate (userId, title) pairs
ratings_agg_df = merged_df.groupby(['userId', 'movieId']).rating.mean().reset_index()
ratings_agg_df.head()
| userId | movieId | rating | |
|---|---|---|---|
| 0 | 1 | 1 | 0.429960 |
| 1 | 1 | 1036 | 1.369846 |
| 2 | 1 | 1049 | -0.509926 |
| 3 | 1 | 1066 | 0.429960 |
| 4 | 1 | 110 | 0.429960 |
Convert to sparse
If you want to search across numerous reviews from different users, you can represent these reviews in a sparse matrix.
# Convert ratings to sparse vectors
user_sparse_vectors = defaultdict(lambda: {"values": [], "indices": []})
for row in ratings_agg_df.itertuples():
user_sparse_vectors[row.userId]["values"].append(row.rating)
user_sparse_vectors[row.userId]["indices"].append(int(row.movieId))
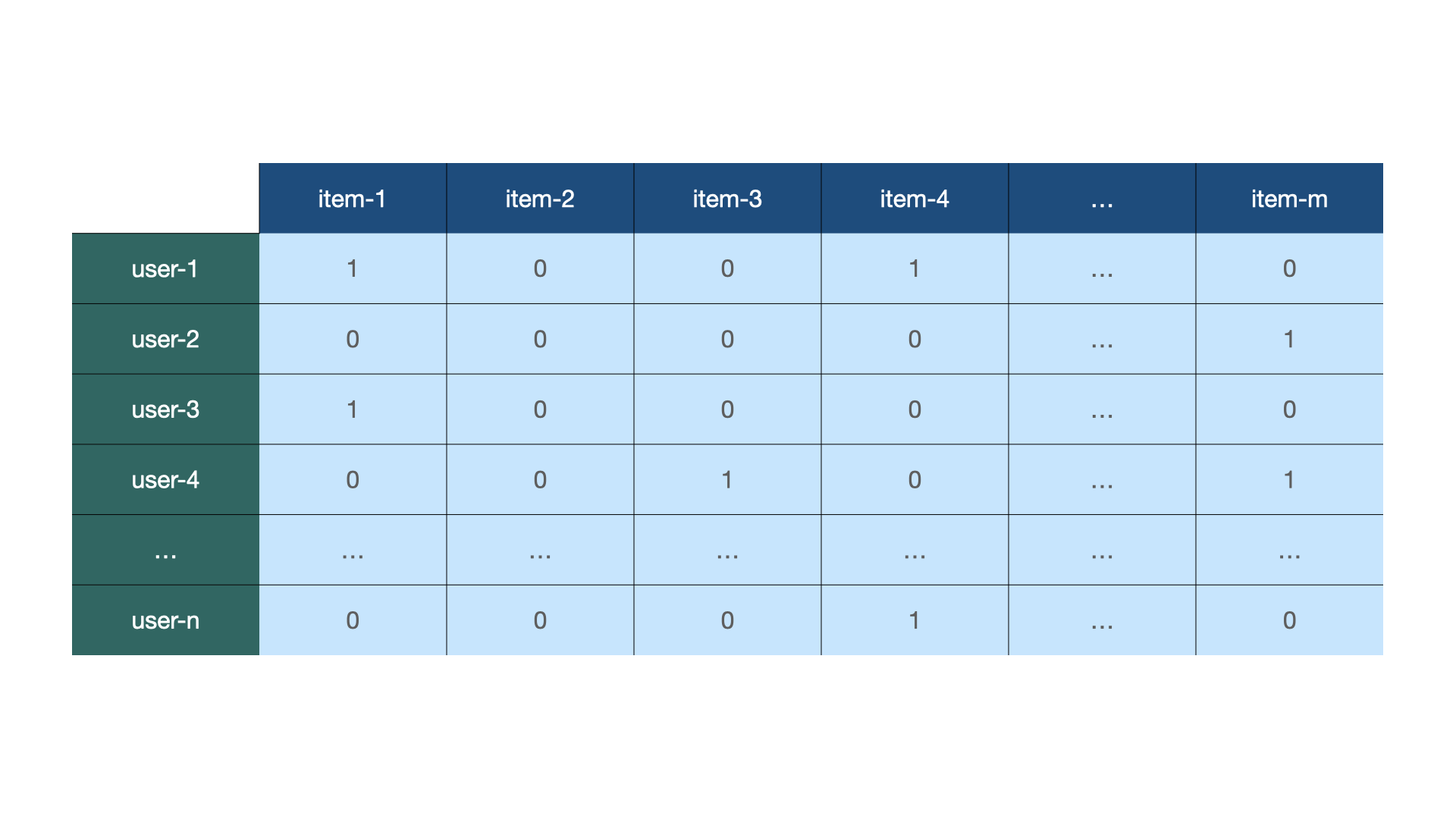
Upload the data
Here, you will initialize the Qdrant client and create a new collection to store the data.
Convert the user ratings to sparse vectors and include the movieId in the payload.
# Define a data generator
def data_generator():
for user_id, sparse_vector in user_sparse_vectors.items():
yield PointStruct(
id=user_id,
vector={"ratings": SparseVector(
indices=sparse_vector["indices"],
values=sparse_vector["values"]
)},
payload={"user_id": user_id, "movie_id": sparse_vector["indices"]}
)
# Upload points using the data generator
qdrant_client.upload_points(
collection_name=collection_name,
points=data_generator()
)
Define ratings
my_ratings = {
603: 1, # Matrix
13475: 1, # Star Trek
11: 1, # Star Wars
1091: -1, # The Thing
862: 1, # Toy Story
597: -1, # Titanic
680: -1, # Pulp Fiction
13: 1, # Forrest Gump
120: 1, # Lord of the Rings
87: -1, # Indiana Jones
562: -1 # Die Hard
}
# Create sparse vector from my_ratings
def to_vector(ratings):
vector = SparseVector(
values=[],
indices=[]
)
for movie_id, rating in ratings.items():
vector.values.append(rating)
vector.indices.append(movie_id)
return vector
Run the query
From the uploaded list of movies with ratings, you can perform a search in Qdrant to get the top recommendations, focusing on the most similar ones.
If you have a list of movies we like and dislike, you can search for the top 20 users with the most similar tastes to ours. By doing this, you can discover the most liked movies that you haven’t seen yet by looking at those users’ review lists.
# Perform the search
results = qdrant_client.search(
collection_name=collection_name,
query_vector=NamedSparseVector(
name="ratings",
vector=to_vector(my_ratings)
),
limit=20
)
You can filter the results to order by score and sort them to get the top 5 movies.
# Convert results to scores and sort by score
def results_to_scores(results):
movie_scores = defaultdict(lambda: 0)
for result in results:
for movie_id in result.payload["movie_id"]:
movie_scores[movie_id] += result.score
return movie_scores
# Convert results to scores and sort by score
movie_scores = results_to_scores(results)
top_movies = sorted(movie_scores.items(), key=lambda x: x[1], reverse=True)
Display the results
Finally, we display the top 5 recommended movies along with their posters and titles.
# Create HTML to display top 5 results
html_content = "<div class='movies-container'>"
for movie_id, score in top_movies[:5]:
imdb_id_row = links.loc[links['movieId'] == int(movie_id), 'imdbId']
if not imdb_id_row.empty:
imdb_id = imdb_id_row.values[0]
poster_url, movie_info = get_movie_poster(imdb_id, omdb_api_key)
movie_title = movie_info.get('Title', 'Unknown Title')
html_content += f"""
<div class='movie-card'>
<img src="{poster_url}" alt="Poster" class="movie-poster">
<div class="movie-title">{movie_title}</div>
<div class="movie-score">Score: {score}</div>
</div>
"""
else:
continue # Skip if imdb_id is not found
html_content += "</div>"
display(HTML(html_content))
Recommendations
For a complete display of movie posters, check the notebook output. Here are the results without html content.
Toy Story, Score: 131.2033799
Monty Python and the Holy Grail, Score: 131.2033799
Star Wars: Episode V - The Empire Strikes Back, Score: 131.2033799
Star Wars: Episode VI - Return of the Jedi, Score: 131.2033799
Men in Black, Score: 131.2033799
Conclusion
As demonstrated, it is possible to build an interesting movie recommendation system without intensive model training using Qdrant and Sparse Vectors. This approach not only simplifies the recommendation process but also makes it scalable and interpretable. In future tutorials, we can experiment more with this combination to further enhance our recommendation systems.